기본 정렬 알고리즘 [Selection, Insertion, Bubble]
in algorithm / Algorithm on Algorithm, Sort, Github, Git Last modified at:
- 기본 정렬 알고리즘에 대해서 정리하는 글입니다.
- selection sort, bubble sort, insertion sort
- 시간 복잡도에 대해서 생각해봅니다.
#1 선택 정렬 (Selection Sort)
-방식
- 첫 번째 배열에 저장되어 있는 값과 배열 전체를 비교해 최소값을 넣는다.
- 다음의 배열에 저장되어 있는 값과 배열 전체를 비교해 최소값을 넣는다.
- 배열이 끝날 때 까지 반복한다.
ex)
다음과 같은 배열이 있습니다. [8, 7, 5, 4, 6]
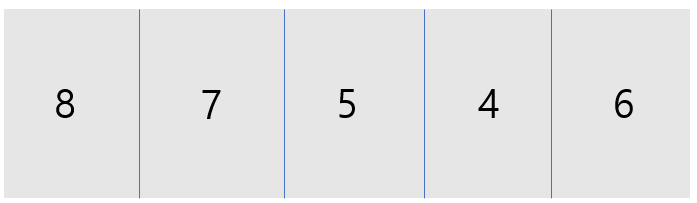
먼저 첫 번째 저장되어 있는 배열[값 : 8]이 i가 되고 그 다음 배열 7부터 j로 비교를 시작합니다. 그 중 가장 작은 수의 배열[값 : 4] minIdx는 3이 됩니다.
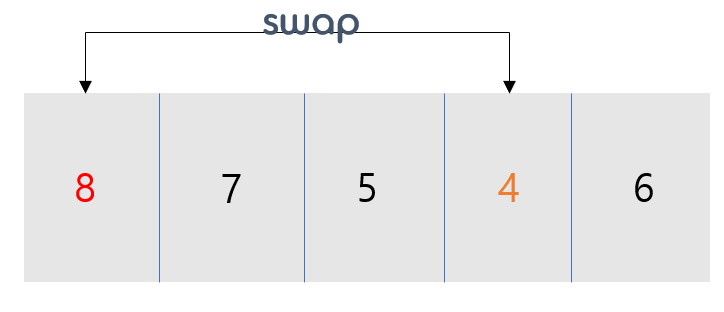
다음 i가 증가하고 j는 i다음부터 시작이 되어집니다. 따라서 가장 작은 minIdx 2와 i를 swap합니다.
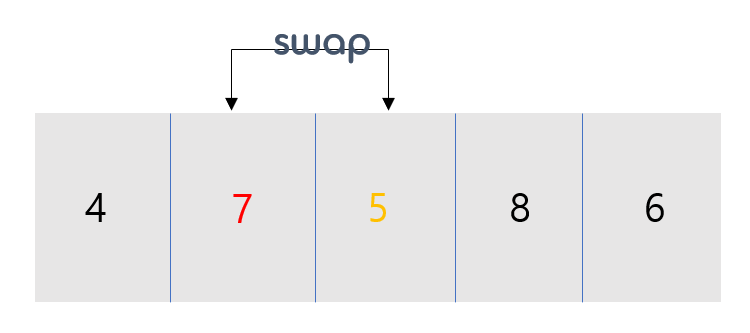
이전 과정과 동일합니다.
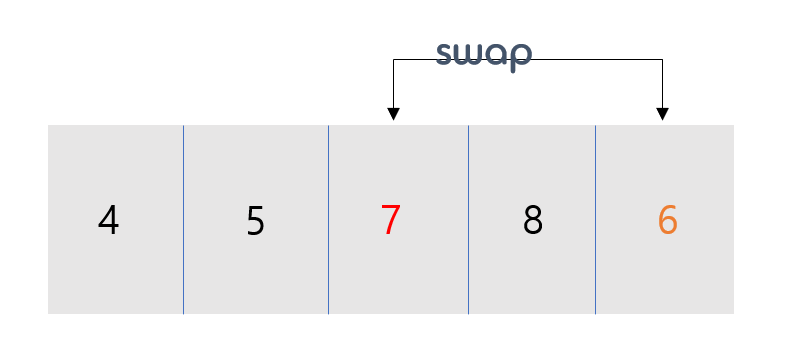
이전 과정과 동일하고, 배열의 끝까지 완료되었기 때문에 오름차순 정렬이 되었습니다.
시간 복잡도
배열의 데이터 n개 일 때,
- 첫 번째 과정, 배열 1번 ~ 배열 n-1번 비교 -> (n-1)번
- 두 번째 과정, 배열 2번 ~ 배열 n-1번 비교 -> (n-2)번
- …….. 반복
- (n-1) + (n-2) + (n-3) + …… + 2 + 1 -> n(n-1)/2
- 최선 최악 평균의 시간복잡도는 O(n^2)으로 동일하다
Selection Sort 장점
- 구현이 쉬운 편이지만, 비교 횟수에 비해서 교환 횟수는 적기 때문에 많은 교환이 일어나야 하는 자료에서 효율적일 수 있다.
- 정렬하고자 하는 배열 안에서 교환하는 방식으로, 다른 메모리 공간을 필요로 하지 않는 in-place sorting(제자리 정렬)이다.
Selection Sort 단점
- 시간 복잡도가 O(n^2)으로 비효율적이다.
구현 코드
#2 버블 정렬 (Bubble Sort)
-방식
- 현재 배열의 값과 다음의 배열의 값을 비교하여 정렬하는 방식입니다.
- 첫 번째 배열을 돌 때 가장 큰 값이 맨뒤로 가게 되므로, 다음 번 배열을 돌 때 맨 뒤의 값은 제외되는 방식으로 진행됩니다[오름차순 기준].
ex)
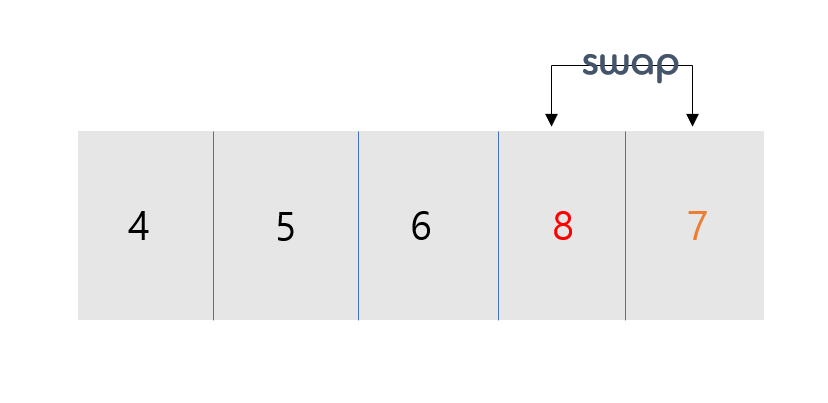
- 다음과 같은 배열이 있습니다. [8, 7, 5, 4, 6]
- 현재 기준 첫 번째 배열의 index가 i번째, 다음의 배열의 index j(i+1)과 비교하여 조건에 따라 swap을 하게 됩니다.
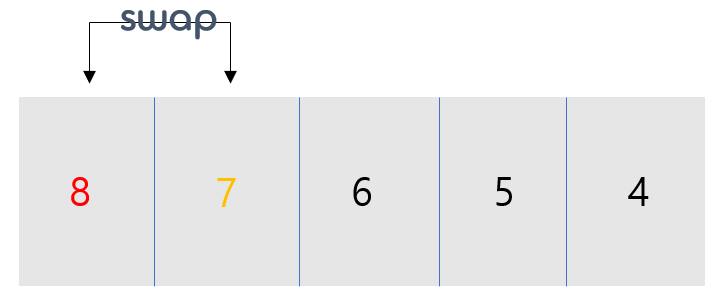
- 이전 과정에서의 j번 index가 i로, j번 인덱스는 i+1로 바뀌게 되고 조건에 따라 swap을 하게됩니다.
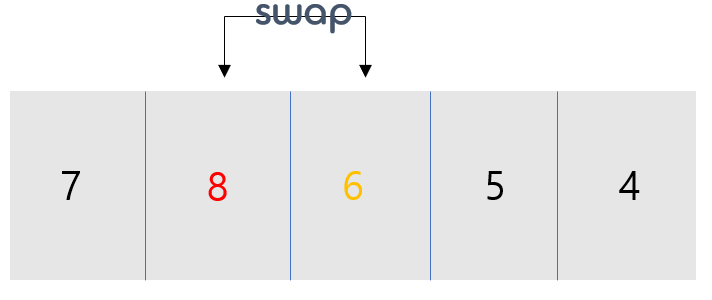
- 위의 과정과 동일합니다.
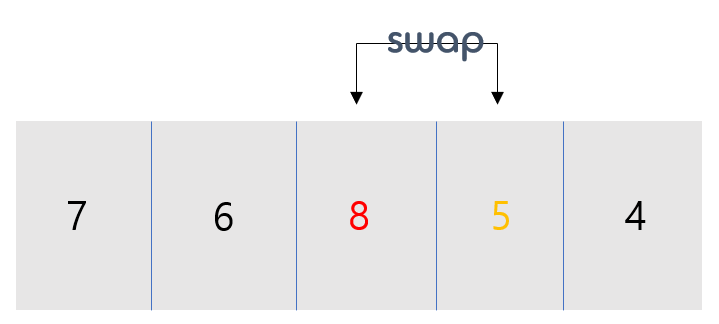
- 위의 과정과 동일합니다.
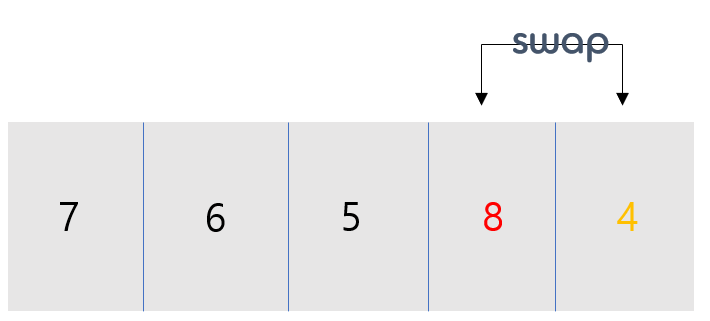
- 첫 번째 회전을 할 때, 다음과 같이 가장 큰 배열이 마지막 배열에 들어가게 되고 다음 번 회전에서 제외되게 됩니다.[오름차순 기준]

- 한 번의 회전에 큰 수를 오른쪽에 넣음으로써, 하나씩 줄여가면서 반복됩니다.
시간 복잡도
-> 배열의 데이터 n개 일 때,
- 첫 번째 과정, 배열 0번, 1번 / 1번,2번 / …. / n-2번, n-1번 비교 -> (n-1)번
- 두 번째 과정, 배열 0번, 1번 / 1번,2번 / …. / n-3번, n-2번 비교 -> (n-2)번
- …….. 반복
- (n-1) + (n-2) + (n-3) + …… + 2 + 1 -> n(n-1)/2
- 최선 최악 평균의 시간복잡도는 O(n^2)으로 동일하다
Selection Sort 장점
- 구현이 쉬운 편이지만, 비교 횟수에 비해서 교환 횟수는 적기 때문에 많은 교환이 일어나야 하는 자료에서 효율적일 수 있다.
- 정렬하고자 하는 배열 안에서 교환하는 방식으로, selection sort와 동일하게 다른 메모리 공간을 필요로 하지 않는 in-place sorting(제자리 정렬)이다.
Selection Sort 단점
- 시간 복잡도가 O(n^2)으로 비효율적이다.
구현 코드
#3 삽입 정렬
방식
- 삽입 정렬은 key값과 앞의 배열들을 비교하여서 정렬하는 알고리즘입니다.
- 최적의 시간은 O(n)으로 빠른 시간내에 수행을 할 수 있습니다.
- key값 보다 큰 값들은 뒤로 밀고, 작은 값을 만나면 그 뒤 위치에 넣는 방식입니다.
ex)
- 다음과 같은 배열이 있습니다. [8, 7, 5, 4, 6]
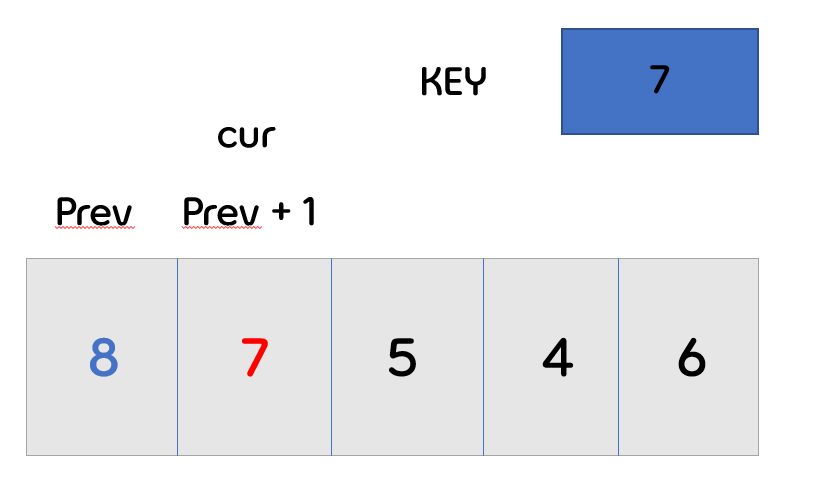
- key값의 인덱스는 1번부터 시작합니다. 0번부터 시작할 시, 앞의 비교할 배열이 없기 때문에 그렇습니다.
- 다음과 같이 1번 인덱스의 7번이 key값이 되고 key앞의 값 8과 비교를 시작합니다.
- 앞의 배열 8이 key값 보다 크기 때문에 key 값이 앞으로 가게 됩니다.
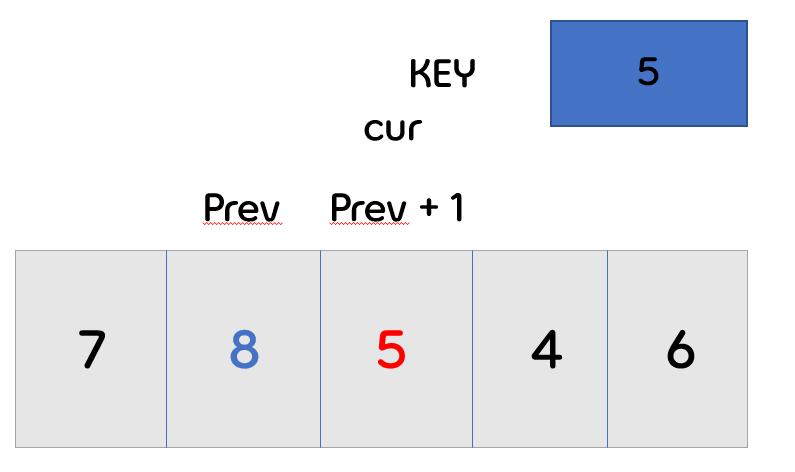
- 이제 cur를 증가시켜, key값이 2번 배열의 값 5로 바뀌게 됩니다.
- 먼저 바로 앞의 배열과 비교를 시작합니다.
- 바로 앞의 배열의 값이 key값 보다 크기 때문에 key 값이 앞으로 가게 됩니다.
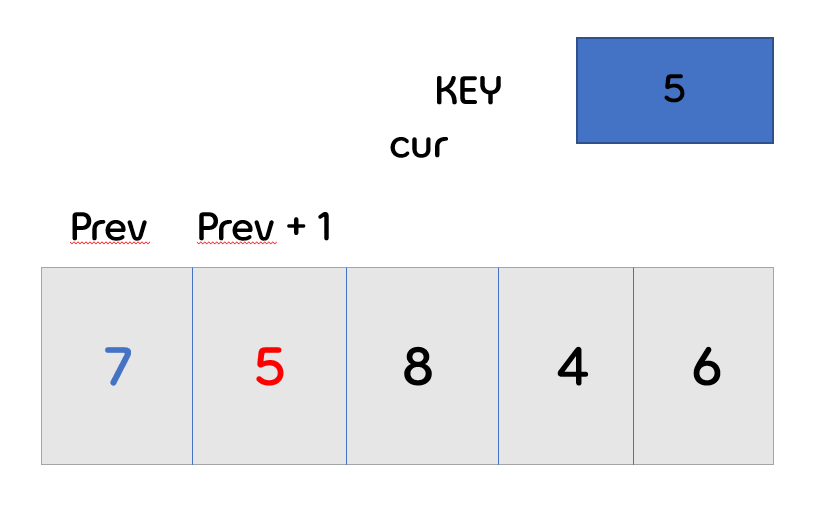
- 그리고 0번 배열과 비교를 하게 됩니다.
- 0번 배열의 값 7보다 key값이 작기 때문에 0번 배열이 뒤로 밀리게 됩니다.
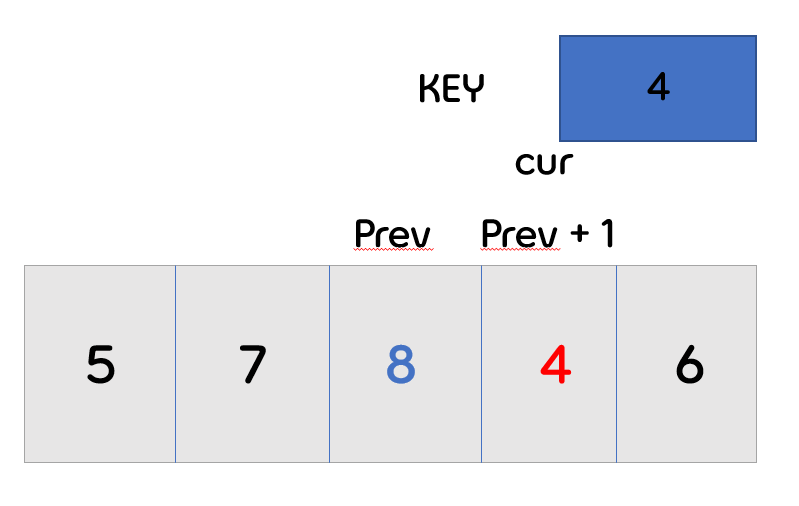
- 앞의 배열이 더 이상 존재하지 않으므로, 다음 번의 cur가 key값으로 바뀌게 됩니다.
- 위의 과정과 동일하게 바로 앞의 2번 인덱스의 값과 key값을 비교 합니다.
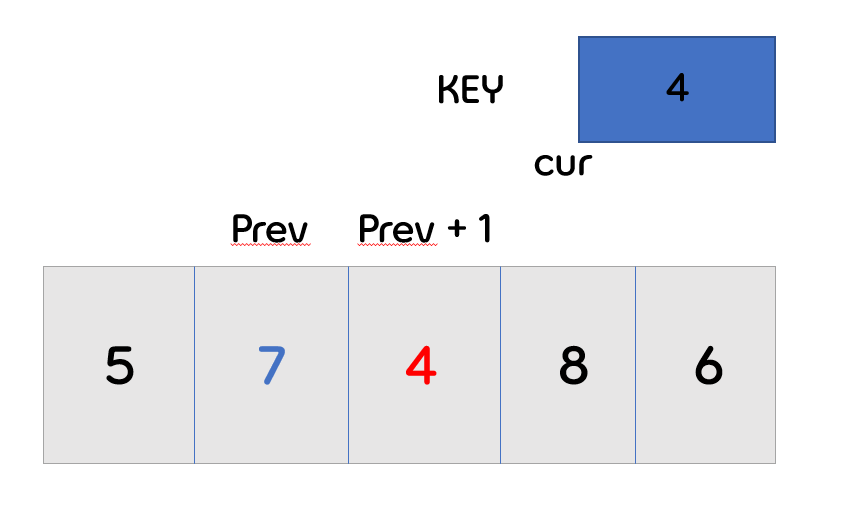
- 위의 과정과 동일하게 1번 인덱스의 값과 key값을 비교 합니다.
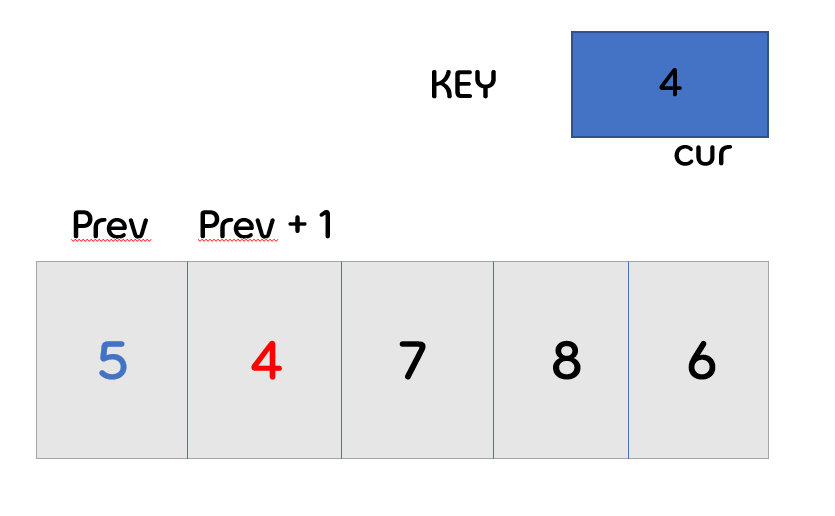
- 위의 과정과 동일하게 0번 인덱스의 값과 key값을 비교 합니다.
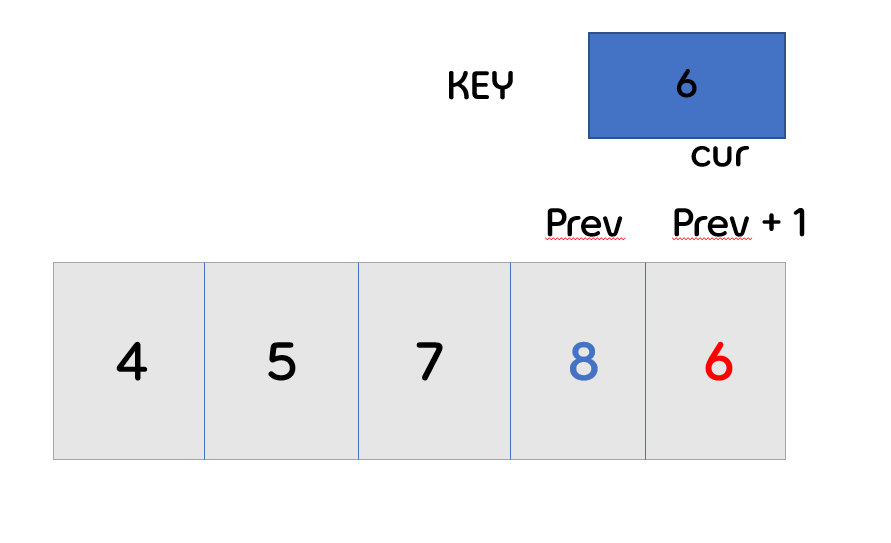
- 더 이상 앞의 배열이 존재하지 않으므로, 다음 번의 cur가 key값으로 바뀌게 됩니다.
- 앞의 배열의 값과 key값을 비교를 합니다.
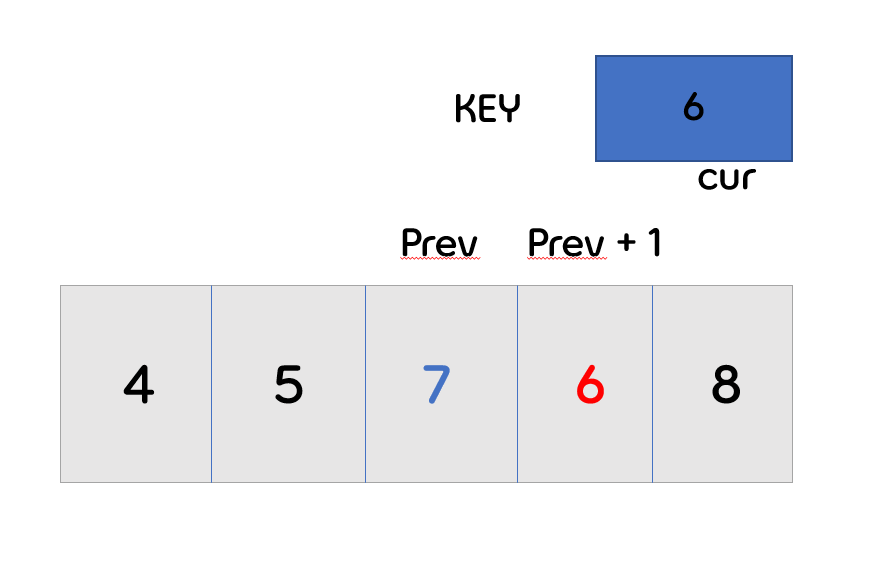
- 위의 과정과 동일하게 3번 인덱스의 값과 key값을 비교 합니다.
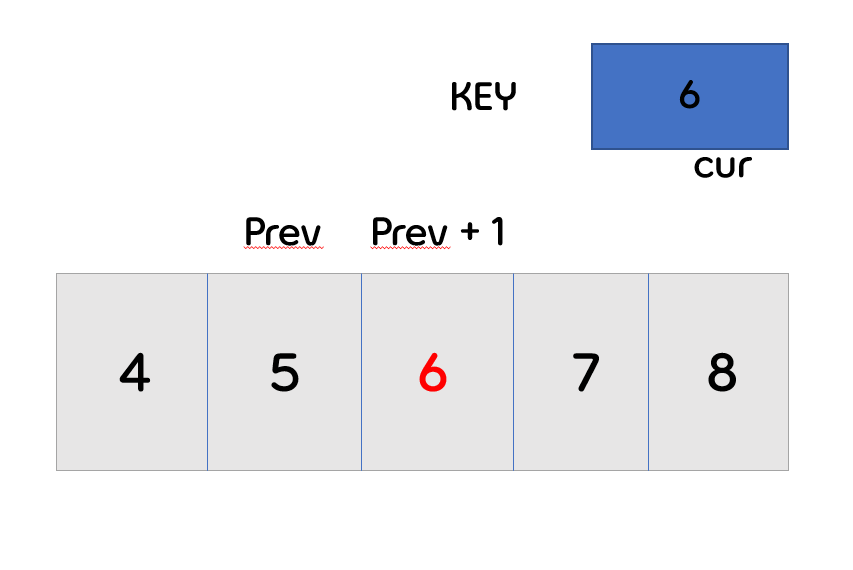
- 1번 인덱스의 값과 key값을 비교를 진행합니다.
- 1번 인덱스의 값이 key값보다 작으므로, key는 해당 자리에 삽입합니다.
- 최종 정렬 결과입니다.
Insertion Sort 장점
- 이미 정렬되어 있는 경우나, 자료의 수가 적은 경우 효율적입니다.
- 바로 앞의 데이터와 비교를 하므로 안정적인 정렬입니다.
- 정렬하고자 하는 배열 안에서 교환하는 방식으로, 앞의 두 정렬과 동일하게 다른 메모리 공간을 필요로 하지 않는 in-place sorting(제자리 정렬)이다.
Insertion Sort 단점
- 평균과 최악의 시간복잡도가 O(n^2)으로 비효율적입니다.
시간복잡도
- Best-case : O(n)
정렬된 데이터들이 들어오게 되면 바로 앞의 데이터와의 비교로만 이루어지므로, n-1번 수행되게 됩니다. 따라서 O(n)시간 입니다.
- Worst, Average : O(n^2)
- 역정렬된 데이터들이 들어오게 되면 (n-1) + (n-2) + (n-3) + …. + 2 + 1로, O(n^2)의 시간이 들어오게 됩니다.